Датасет
Датасет - материализованный набор данных в виде таблицы в БД, рассчитанный в разрезе выбранной сущности на данных, зарегистрированных в приложении.
Назначение - получение выборок данных для:
- Задач машинного обучения
- Анализ данных
- Промежуточное звено трансформации данных
Способы получения датасета:
- Создание согласно конфигурации (конструктор)
- Загрузка из источника с помощью загрузчика (сегмент)
- Нарезка другого датасета на части (стратификация)
- Замена пустых значений (импутация) другого датасета
Конфигурация датасета через конструктор
Классический вариант создания датасета.
Представляет собой следующую последовательность действий:
- Выбор сущности датасета
Создание нового датасета в SDK:
from catalogue import dataset as ds
new_ds = ds.create(
entity_ds: ent.CUSTOMER, # указывается объект Entity, сущность датасета
name: "my_giga_dataset", # название датасета
description: "customer transactions through the agreements", # описание
)
- Выбор сегмента (опционально) - датасет-источник значений сущности.
- Сегментом может выступать любой датасет из каталога.
- Если сегмент не выбран, то в конфигурируемый датасет отбираются значения сущности всех используемых версий переменных, загруженных под сущностью датасета.
Конфигурация сегмента в SDK:
- Выбор даты расчёта по состоянию на которую рассчитываются переменные:
- Актуальный срез
- Даты из календаря
- Даты из сегмента (только если выбран сегмент и в сегменте есть дата)\
Настройка даты актуальности датасета в SDK:
- Конфигурация переменных датасета - можно использовать:
- Готовые переменные из каталога
- Предагрегаты из каталога - настраиваются агрегирующие функции и условия фильтрации:
- Агрегирующие функции - max, min, avg, count, sum, count_rows (количество строк), count_distinct (количество уникальных, аналог count(1))
- В условиях фильтрации могут использоваться:
- Переменные из того же предагрегата, что и агрегируемая переменная
- Дата актуальности. Настройка периода агрегации по дате актуальности обязательна для транзакционных предагрегатов
- Переменные из сегмента
- Ключи связанных сущностей
- Расчетные переменные на основе сконфигурированных переменных из датасета (пользовательские формулы второго уровня). Доступные функции для пользовательских формул описаны ниже.
Добавление фичей в датасет в SDK:
# Готовая фича
new_ds = ds.create(ent.CUSTOMER, name='test_ds')
new_ds.add_feature(
features=[
Features.<Feature_Name>.<Feature_Version_Name>.alias('my_new_alias')
],
link: List[EntityLink]
)
# Агрегированная фича
new_ds = ds.create(ent.CUSTOMER, name='test_ds')
new_ds.add_feature(
features=[
Features.<Feature_Name>.<Feature_Version_Name>.alias('my_new_alias')
],
link: List[EntityLink],
agg: List[Function], # func.sum(), func.avg() etc.
domain: List[FeatureExpression]
)
# Ключ связанной сущности
new_ds = ds.create(ent.CUSTOMER, name='test_ds')
new_ds.add_feature(
ent.AGREEMENT.AGREEMENT_RK.alias('agreement_rk_linked').link(el.link_CUSTOMER_x_AGREEMENT)
)
- Выбор итоговых переменных для включения в поля датасета - например, некоторые переменные могут использоваться только для фильтрации записей, но не должны фигурировать в итоговой таблице датасета.
- Настройка условий фильтрации с использованием любых сконфигурированных переменных датасета. Синтаксис условия совпадает с пользовательскими формулами второго уровня.
Настройка фильтра в SDK:
- Выбор рассчитываемых статистических показателей для полей датасета. (опционально)
Имена переменных датасета должны быть уникальны в таблице датасета и не пересекаться с физическими названиями других полей датасета (ключи зерна, дата расчета, технические поля - created_dttm, run_rk)
Цепочки связей зерен
При конфигурировании сегмента и переменных датасета возможно использование цепочек связей сущностей.
Цепочка связей сущностей представляет собой последовательность связей по которой осуществляется переход
от сущности датасета к сущности используемого объекта. Ограничение - в цепочке связей не может использоваться
более одной автоматический связи подряд.
Если сущность используемого объекта не совпадает с сущностью датасета,
то указание цепочки связей является обязательным.
Если в цепочке связей для переменной присутствует связь, приводящая к размножению записей,
то такая переменная всегда конфигурируется как предагрегат.
В датасете должна быть выбрана хотя бы одна версия переменной, загруженная под сущностью датасета или сегмент под сущностью датасета (без использования связей).
Функции пользовательских формул
При конфигурации переменных датасета допускается использование формул с использованием
математических операторов (сложение, умножение, сравнение etc.),
а так же SQL функций, таких как between, like, date_add etc.
Пользовательские функции и формулы в SDK:
func.and_(
ds_feat.str_feature.not_like('%A'),
ds_feat.num_feature > 1000
).alias('TEST_LVL2_FEATURE')
func.coalesce(
ds_feat.num_feature,
ds_feat.num_feature_2,
else_=-1
).alias('TEST_LVL2_FEATURE')
ds_feat.SOME_FEATURE.lead(
offset=1,
partition_by=[
ds_feat.CITY
],
order_by=[
ds_feat.CUSTOMER_AGE
]
).alias('LEAD2_SOME_FEATURE')
func.ltrim(
ds_feat.str_feature_1
).alias('TEST_LVL2_FEATURE')
func.date_part(
ds_feat.date_feature,
'minute'
).alias('TEST_LVL2_FEATURE')
Пример конфигурирования предагрегата
В процессе конфигурирования предагрегатов производится настройка агрегирующих функций и условий фильтрации агрегируемых данных. Итоговый набор переменных датасета генерируется по формуле:
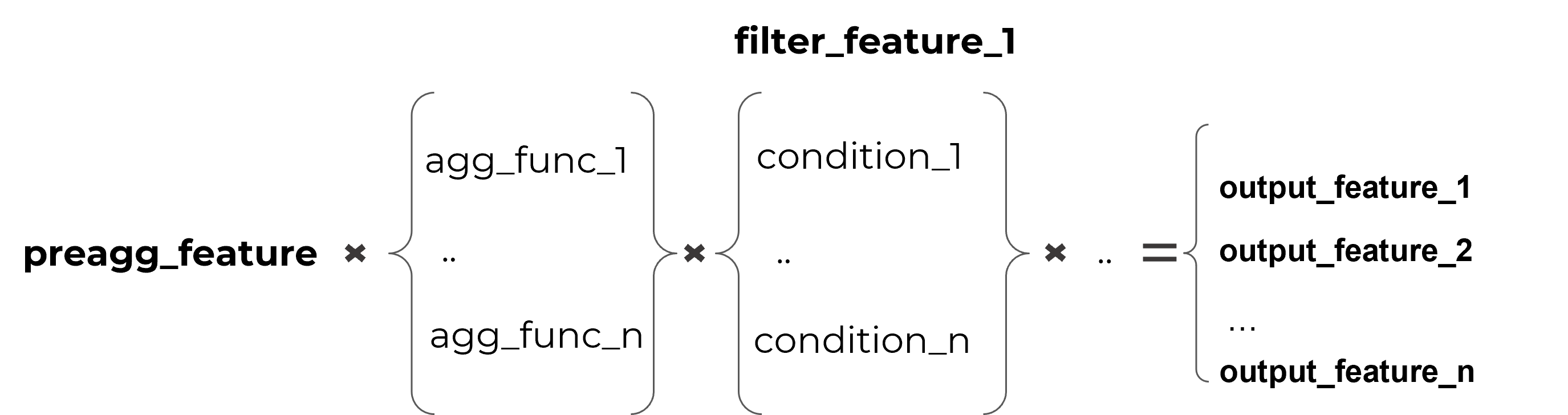
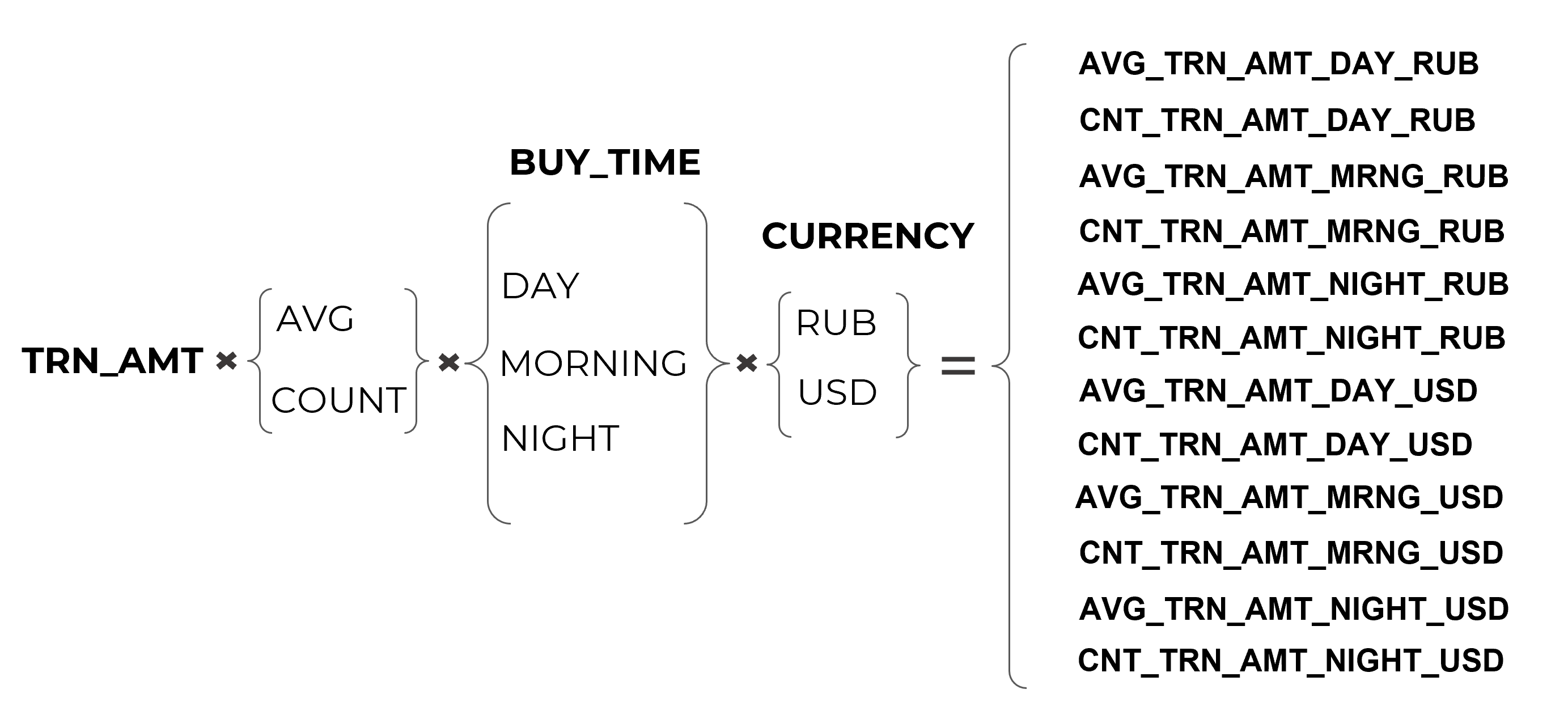
Пример - конфигурация предагрегата TRN_AMT:
- Агрегирующие функции - AVG, COUNT
- Условия фильтрации по версии фичи BUY_TIME:
- = MORNING
- = DAY
- = NIGHT
- Условия фильтрации по версии фичи CURRENCY:
- = RUB
- = USD
Итоговый набор переменных датасета:
- AVG_TRN_AMT_DAY_RUB (
AVG&BUY_TIME = DAY&CURRENCY = RUB) - CNT_TRN_AMT_DAY_RUB (
COUNT&BUY_TIME = DAY&CURRENCY = RUB) - AVG_TRN_AMT_MRNG_RUB (
AVG&BUY_TIME = MORNING&CURRENCY = RUB) - CNT_TRN_AMT_MRNG_RUB (
COUNT&BUY_TIME = MORNING&CURRENCY = RUB) - AVG_TRN_AMT_NIGHT_RUB (
AVG&BUY_TIME = NIGHT&CURRENCY = RUB) - CNT_TRN_AMT_NIGHT_RUB (
COUNT&BUY_TIME = NIGHT&CURRENCY = RUB) - AVG_TRN_AMT_DAY_USD (
AVG&BUY_TIME = DAY&CURRENCY = USD) - CNT_TRN_AMT_DAY_USD (
COUNT&BUY_TIME = DAY&CURRENCY = USD) - AVG_TRN_AMT_MRNG_USD (
AVG&BUY_TIME = MORNING&CURRENCY = USD) - CNT_TRN_AMT_MRNG_USD (
COUNT&BUY_TIME = MORNING&CURRENCY = USD) - AVG_TRN_AMT_NIGHT_USD (
AVG&BUY_TIME = NIGHT&CURRENCY = USD) - CNT_TRN_AMT_NIGHT_USD (
COUNT&BUY_TIME = NIGHT&CURRENCY = USD)
Загрузка датасета из источника
Добавление нового датасета в каталог датасетов возможно через загрузчик (назначение загрузчика - segment).
Датасет, полученный таким образом, может быть использован при конфигурации нового датасета в конструкторе.
Стратификация
Получение новых датасетов из частей другого датасета из каталога в результате его нарезки датасета
по заданным правилам.
Стратификация осуществляется в три этапа:
- Группировка по указанным полям датасета
- Сортировка данных перед нарезкой
- Нарезка датасета, полученного в результате манипуляций в п.1 и п.2, на указанные в конфигурации части
Для стратификации доступны датасеты, полученные через конструктор или зарегистрированные загрузчиком.
Стратификация в SDK:
from FSClient.catalogue import dataset # Каталог датасетов
ds_feautures = ds.My_Dataset.get_feautures() # получение каталога фичей стратифицируемого датасета
ds.My_Dataset.split(
parts=[ # выбор размера и названий выборок
(<int размер выборки1>, <str, название выборки1>),
..
(<int размер выборкиN>, <str, название выборкиN>)
],
group=[ # optional - группировка по фичам датасета
ds_feautures.my_feature_1,
..
ds_feautures.another_feature_n
] = None,
sort=[ # optional - сортировка исходного датасета перед стратификацией
# по значениям фичей или ключей с заданными параметрами
(ds.My_Dataset.entity.my_key_1, 'asc nulls_last'), # сортировка по ключу
# доступная конфигурация asc/desc nulls_last/nulls_first
# Default value 'asc nulls_last'
(ds_feautures.my_feature_1, 'desc'), # сортировка по фиче
..
] = None,
name=str # базовое имя датасета, при значении не None заменяет название исходного датасета
)
Импутация
Создаёт новый датасет на базе существующего с заменой пустых значений в столбцах на результат импутитирующей функции.
Требования:
- Исходный датасет должен быть непустым
- Структура нового датасета полностью совпадает со структурой исходного датасета
- Поля из исходного датасета, не определенные в правилах импутации, копируются в новый датасет as-is
- Если переданы поля группировки, то данные для импутации агрегируются в разрезе переданных полей, иначе рассчитываются общие агрегаты для всего датасета
- После завершения расчета нового датасеты выполняется расчет базовых статистических показателей
Доступные функции для импутации:
- mean – среднее арифметическое
- min – минимальное значение
- max – максимальное значение
- median – медианное значение
- mode - мода, самое частое значение
- const – константа из "VALUE"
Импутация в SDK:
from FSClient.catalogue import (
dataset,
function
)
new_ds = dataset.My_Dataset.impute( # Returns an imputation dataset obj.
name = 'new_dataset',
description = 'new_dataset description'
)
output = new_ds.get_features() # local features catalogue from current dataset
new_ds.add_rule(
features=[output.any_feature, 'my_another_feature'], # feature from output catalogue
# or feature name as str
func=function.median(), # avg, median, mode, max, min, const from function catalogue
# feature from output catalogue
# or feature name as str
# or datasets entity key
# or report_dttm
group=[output.some_feature, new_ds.entity.customer_entity_key, 'report_dttm'],
const=50 # constant value of imputation
)
new_ds.save_x_execute()