Before start
Установка:
# из репозитория
pip install FSClient --index-url https://__token__:<token secret>@git.angara.cloud/api/v4/projects/535/packages/pypi/simple
# .whl/tar.gz (должен находиться в той же папке, что и ноутбук .ipynb)
pip install FSClient.whl
Подключение к приложению из SDK необходимо выполнять в начале каждой сессии перед импортом каталогов:
from FSClient import _connect
_connect(
url='https://<%morphism_url>/api',
username='some_user',
password='some_password'
)
Подготовка к регистрации данных
Проверить, что выполнена инициализирующая загрузка справочников типов данных.
Для работы с сущностями, фичами и другими объектами в приложении используется система каталогов. Начало работы с каталогом сущностей:
Для просмотра каталога сущностей необходимо вызвать каталог, который вернет каталог в формате таблицы:
Создание новых сущностей осуществляется через вызов функции create из соответствующего каталога.
Начнем с данных о клиенте.
В первую очередь необходимо подготовить мета-сущность клиента в приложении.
Название сущности и ключа не обязательно должно быть таким же, как в таблице с данными,
т.к. при регистрации данных происходит сопоставление ключей и полей в явном виде.
Выполняем создание новой сущности CUSTOMER, у которой будет один ключ - CUSTOMER_RK:
customer = entity.create() # <-- получение объекта новой сущности
customer.config = {
'name': 'CUSTOMER', # <-- имя сущности
'description': 'Клиент', # <-- пользовательское описание сущности
'entity_keys': [ # <-- список ключей сущности
{
'name': 'CUSTOMER_RK', # <-- название ключа
'description': 'Суррогатный ключ клиента', # <-- пользовательское описание ключа
'data_type': dttp.INT # <-- тип данных ключа
}
]
}
customer.save() # <-- регистрация сущности
Создание фичи осуществляется через каталог фичей, выполняем импорт каталога фичей:
Для определения признаков из таблицы необходимо зарегистрировать фичи, с которыми мы их свяжем в приложении:
new_feat = feature.create()
new_feat.config = {
'name': 'GENDER', # <-- Название фичи
'description': 'Пол' # <-- Пользовательское описание фичи
}
new_feat.save() # <-- регистрация фичи
Название фичи так же не обязательно должно быть таким же, как поле в таблице с данными.
new_feat = feature.create()
new_feat.config = {
'name': 'AGE',
'description': 'Возраст клиента'
}
new_feat.save()
new_feat = feature.create()
new_feat.config = {
'name': 'CITY',
'description': 'Наименование города'
}
new_feat.save()
Теперь можно приступить к регистрации таблицы CUSTOMER_INFO. Процесс регистрации данных является описанием таблицы. Это позволяет выполнять операции с данными без участия пользователя в дальнейшем.
Первый шаг в регистрации загрузчика - выбор источника данных (БД) и адреса таблицы (схема + название). Название и описание загрузчика являются мета-полями и предназначены для идентификации источника данных в каталоге приложения.
В нашем случае источником данных является таблица в БД. Подробнее о других источниках будет далее.
from FSClient.catalogue import (
entity as ent, # <-- Для удобства использования каталог в коде используем сокращения
feature as feat,
loader as load
)
new_loader = load.create(
source='table' # <-- Тип источника данных
)
new_loader.config = {
# Название источника данных в каталоге
'loader_name': 'CUSTOMER_INFO_HIST',
# Пользовательское описание источника данных
'description': 'Информация по клиенту из карточки клиента АБС',
# Схема таблицы
'src_schema_name': 'stage',
# Название таблицы
'src_table_name': 'customer_hist',
# Сущность таблицы
'entity': ent.CUSTOMER
}
После выбора источника данных необходимо определить соответствие между полями таблицы и логическими сущностями приложения:
- В аргументе
entityуказываем, какие поля таблицы источника соответствуют ключам выбранной сущности - В аргументе
featuresсвязываем фичи из каталога приложения с полями таблицы
new_loader.mapping = {
'entity': [
{
# Выбор ключа сущности из каталога
'entity_key': ent.CUSTOMER.CUSTOMER_RK,
# Название поля из таблицы, соответствующее выбранному ключу
'stg_column_name': 'customer_rk'
}
],
'features': [
{
# Фича из каталога
'feature': feat.CUSTOMER_AGE,
# Название поля из таблицы
'stg_column_name': 'customer_age',
'feature_version_config': {
# Название версии фичи в каталоге
'name': 'V1_MAIN',
# Пользовательское описание версии фичи
'description': 'Карточка клиента из АБС: Возраст клиента',
# Тип данных поля из таблицы
'data_type': dttp.INT
}
},
{
'stg_column_name': 'gender',
'feature': feat.GENDER,
'feature_version_config': {
'name': 'V1_MAIN',
'description': 'Карточка клиента из АБС: Пол',
'data_type': dttp.STRING
}
},
{
'stg_column_name': 'city',
'feature': feat.CITY,
'feature_version_config': {
'name': 'V1_MAIN',
'description': 'Карточка клиента из АБС: Наименование города',
'data_type': dttp.STRING
}
}
]
}
Процесс связки мета-сущностей из приложения с полями в таблице с данными, проделанный на предыдущем шаге, называется маппинг.
Когда выбран источник и произведен маппинг, следует проверить введенную информацию и после зарегистрировать:
Первый датасет
Датасет - таблица, с использованием данных, зарегистрированных в приложении.
После успешной регистрации загрузчика мы можем создать датасет, используя данные из источника данных, указанного в нашем загрузчике.
Для создания датасета нужен каталог датасетов:
Инициализируем новый датасет:
my_dataset = ds.create(
# Сущность будущего датасета
entity=ent.CUSTOMER,
# Название датасета в каталоге
name='my_first_dataset',
# Пользовательское описание датасета
description='Срез клиентов старше 40 лет'
)
Добавим туда данные о клиенте:
my_dataset.add_feature(
feat.GENDER.V1_MAIN,
feat.CITY.V1_MAIN,
# через alias можно явно определить название поля в датасете
feat.AGE.V1_MAIN.alias('CUSTOMER_AGE')
)
При добавлении данных в датасет мы выбираем именно версию фичи
(в нашем случае версии фич мы назвали V1_MAIN),
т.к. именно она является физическим источником данных бизнес-логики фичи.
Чтобы не копировать источник данных, только в виде датасета, отфильтруем клиентов по возрасту.
Для начала нам следует получить локальный каталог полей датасета:
Зададим условие фильтрации данных в нашем датасете "Клиенты, возраст которых старше 40 лет":
Для регистрации датасета и запуска расчета выполняем соответствующую функцию:
Обновим каталог, чтобы посмотреть информацию о датасете и узнать статус расчета:
from FSClient.catalogue import update
update() # <-- Обновление каталога
ds.my_first_dataset # <-- просмотр информации о датасете
Регистрация предагрегатов
При регистрации источника данных транзакционных предагрегатов в загрузчике появляются новые характеристики данных, такие как: тип гранулярности, значение гранулярности.
Гранулярность данных - минимальный интервал, в разрезе которого собраны данные в строке таблицы.
Таблица CUST_CARD_TRANS_WEEK содержит данные о транзакциях клиента, разбитые по неделям,
значит гранулярность данных "1 неделя".
new_loader = load.create(source = 'table')
new_loader.config = {
'loader_name': 'CUST_CARD_TRANS_WEEK',
'description': 'Транзакции по картам (за неделю) по данным процессинга',
'src_schema_name': 'stage',
'src_table_name': 'cust_card_trans_week',
'preagg_flg': True, # <-- флаг данных-предагрегатов
'granularity_type': 'week', # <-- тип гранулярности
'granularity': 1, # значение гранулярности
'entity': ent.CUSTOMER
}
new_loader.mapping = {
'from_dttm': 'from_dttm',
'entity': [
{
'entity_key': ent.CUSTOMER.CUSTOMER_RK,
'stg_column_name': 'customer_rk'
}
],
'features': [
{
'stg_column_name': 'mcc_categ',
'feature': feat.MCC_CATEG,
'feature_version_config': {
'name': 'CT_W_V1',
'kind': 'feature',
'description': 'Транзакции по картам (за неделю): Категория MCC',
'data_type': dttp.STRING
}
},
{
'stg_column_name': 'channel',
'feature': feat.CHANNEL,
'feature_version_config': {
'name': 'CT_W_V1',
'kind': 'feature',
'description': 'Транзакции по картам (за неделю): Канал совершения транзакции',
'data_type': dttp.STRING
}
},
{
'stg_column_name': 'trn_amt',
'feature': feat.TRN_AMT,
'feature_version_config': {
'name': 'CT_W_V1',
'kind': 'feature',
'description': 'Транзакции по картам (за неделю): Сумма транзакций',
'data_type': dttp.AMOUNT
}
},
{
'stg_column_name': 'trn_cnt',
'feature': feat.TRN_CNT,
'feature_version_config': {
'name': 'CT_W_V1',
'kind': 'feature',
'description': 'Транзакции по картам (за неделю): Количество транзакций',
'data_type': dttp.INT
}
},
{
'stg_column_name': 'last_trn_dt',
'feature': feat.LAST_TRN_DT,
'feature_version_config': {
'name': 'CT_W_V1',
'kind': 'feature',
'description': 'Транзакции по картам (за неделю): Дата совершения последней транзакции',
'data_type': dttp.DATETIME
}
}
]
}
Нам известно, что данные в таблице источнике обновляются раз в месяц, поэтому выставим для загрузчика расписание с обновлением в конце каждого месяца. Таким образом приложение будет хранить актуальные данные и накапливать историю с момента регистрации данных.
new_loader.schedule = { # <-- задаем расписание обновления данных
'type': 'monthly_last_day', # <-- тип расписания "последний день каждого месяца"
'run_time': '23:59:59' # <-- время запуска обновления данных
}
Регистрация загрузчика:
Датасет с агрегатами
Первый источник данных, который мы регистрировали, представлял из себя факты о клиенте, то есть данные в "готовом виде".
Загрузчик CUST_CARD_TRANS_WEEK работает с гранулярными по неделям данными по транзакциям. Для анализа таких данных необходимо выполнять агрегирование, т.к. в "сыром" виде они слишком объемны и нечитаемы.
Инициализируем новый датасет:
my_dataset = ds.create(
entity=ent.CUSTOMER, # <-- Сущность датасета
name='AGG_TRANS_CUSTOMER_DATA',
description='Данные по транзакциям клиентов в разбивке по количеству транзакций'
)
! Выбор сущности датасета открывает доступ ко всем данным, зарегистрированным под этой сущностью. В будущем будет показано, как можно использовать в датасете данные, зарегистрированные под другой сущностью.
Добавим данные о клиенте:
my_dataset.add_feature(
feat.GENDER.V1_MAIN.alias('CUSTOMER_GENDER'),
feat.CITY.V1_MAIN.alias('CUSTOMER_CITY'),
feat.AGE.V1_MAIN.alias('CUSTOMER_AGE')
)
Выполним конфигурацию агрегатов в новом датасете:
from FSClient.catalogue import function as func # <-- каталог функций
my_dataset.add_feature(
features=[
feat.TRN_AMT.CT_W_V1.alias('TRN_AMT') # <-- список версий фичей на агрегирование
],
agg=[ # список агрегирующих функций
func.sum(),
func.max(),
func.min()
],
domain=[
# условие на количество транзакций меньше 10
(feat.TRN_CNT.CT_W_V1 <= 10).set(alias='L10'),
# условие на количество транзакций больше 10
(feat.TRN_CNT.CT_W_V1 > 10).set(alias='M10')
]
)
Результат агрегации версии фичи TRN_AMT.CT_W_V1 по заданным выше параметрам:
3 агрегирующих функции и два противоположных условия по одному и тому же параметру.
Итого 3 x 2 = 6 столбцов с данными:
SUM_TRN_AMT_L10- Сумма транзакций клиента за недели, в которых меньше 10 транзакций;MAX_TRN_AMT_L10- Максимальные траты за неделю среди недель, у которых меньше 10 транзакций;MIN_TRN_AMT_L10- Минимальные траты за неделю среди недель, у которых меньше 10 транзакций;SUM_TRN_AMT_M10- Сумма транзакций клиента за недели, в которых больше 10 транзакций;MAX_TRN_AMT_M10- Максимальные траты за неделю среди недель, у которых больше 10 транзакций;MIN_TRN_AMT_M10- Минимальные траты за неделю среди недель, у которых больше 10 транзакций;
Для регистрации датасета и запуска расчета выполняем соответствующую функцию:
Посмотрим на получившиеся данные. Для этого необходимо вызвать функцию get_dataframe
и передать в нее пользовательское подключение к БД:
<скриншот из жупитера с датафреймом>
Регистрация данных из файла
Помимо таблиц в БД поддерживаются и другие источники, например, данные в формате .csv/.xlsx.
Зарегистрируем данные о договорах клиента, где сущностью является уже не клиент, а клиент+договор.
Для этого нам потребуется создать новую сущность с двумя ключами,
где один уже существует (CUSTOMER_RK):
customer_agreement = ent.create()
customer_agreement.config = {
'name': 'CUSTOMER_AGREEMENT',
'description': 'Клиент-договор',
'entity_keys': [
{
'name': 'AGREEMENT_RK',
'description': 'Суррогатный ключ договора',
'data_type': dttp.INT
},
ent._keys.CUSTOMER_RK # <-- Переиспользуем существующий ключ
]
}
customer_agreement.save() # <-- Регистрация новой сущности
Итого у нас в каталоге две сущности: CUSTOMER и CUSTOMER_AGREEMENT, имеющих один общий ключ.
Для приложения все сущности, у которых есть общий ключ, соединяются автоматической связью, т.к.
через общий ключ данные могут быть связаны. Связь между CUSTOMER и CUSTOMER_AGREEMENT 1:M,
т.к. на одного клиента может приходиться несколько значений клиент+договор.
Связи сущностей могут быть использованы для добавления в датасет версий фичей, сущность которых отличается от сущности датасета. Для этого при их добавлении в датасет нужно указать связь между сущностью датасета и сущностью версии.
Процесс маппинга при регистрации данных из файла не меняется. В конфигурации заменяются несколько аргументов:
new_loader = load.create(source='file')
new_loader.select_file('CUST_AGREEM_FINAL.csv') # <-- загружаем файл с данными
new_loader.config = {
'loader_name': 'CUST_AGREEM_FINAL',
'description': 'test',
'delimiter': ';', # <-- вместо схемы и таблицы указываем разделитель в файле
'entity': ent.CUSTOMER_AGREEMENT
}
! Разделитель указывается в соответствии с тем, какой разделитель полей используется в файле.
new_loader.mapping = {
'from_dttm': 'from_dttm', # <-- Поле с датой начала периода актуальности данных
'entity': [
{
'entity_key': ent.CUSTOMER_AGREEMENT.CUSTOMER_RK,
'stg_column_name': 'customer_rk'
},
{
'entity_key': ent.CUSTOMER_AGREEMENT.AGREEMENT_RK,
'stg_column_name': 'agreement_rk'
}
],
'features': [
{
'stg_column_name': 'agreement_type',
'feature': feat.AGREEMENT_TYPE,
'feature_version_config': {
'name': 'V1_FINAL',
'kind': 'feature',
'description': 'test',
'data_type': dttp.STRING
}
},
{
'stg_column_name': 'contract_cost',
'feature': feat.CONTRACT_COST,
'feature_version_config': {
'name': 'V1_FINAL',
'kind': 'feature',
'description': 'test',
'data_type': dttp.BIG_INT
}
},
{
'stg_column_name': 'vip_flg',
'feature': feat.VIP_FLG,
'feature_version_config': {
'name': 'V1_FINAL',
'kind': 'feature',
'description': 'test',
'data_type': dttp.BIG_INT
}
}
]
}
! Период актуальности данных - определяется двумя датами (from_dttm, to_dttm) и является временным окном, в которое данные в конкретной строчке актуальны и могут быть использованы. Дата начала периода актуальности определяется либо полем в источнике данных, либо задается как значение в формате YYYY-MM-DD hh:mm:ss. Дата конца периода актуальности считается бесконечно далекой датой, если не указана.
Регистрация загрузчика:
Датасет с фичами из другой сущности
my_dataset = ds.create(
entity=ent.CUSTOMER_AGREEMENT, # <-- Сущность датасета
name='CUSTOMER_and_AGREMENT_DATA',
description='Данные о клиенте и его договорах'
)
<Объяснить почему в качестве основной сущности выбрали CUSTOMER_AGREEMENT?>
Добавим данные о договорах клиента:
my_dataset.add_feature(
feat.AGREEMENT_TYPE.V1_FINAL.alias('AGR_TYPE'),
feat.CONTRACT_COST.V1_FINAL.alias('AGR_COST')
)
Добавим данные о клиенте, используя автоматическую связь сущностей (сущность датасета - CUSTOMER_AGREEMENT, сущность данных о клиенте - CUSTOMER)
from FSClient.catalogue import entity_link as el # <-- Импортируем каталог связей сущностей
my_dataset.add_feature(
features=[
feat.GENDER.V1_MAIN.alias('CUSTOMER_GENDER'),
feat.CITY.V1_MAIN.alias('CUSTOMER_CITY'),
feat.AGE.V1_MAIN.alias('CUSTOMER_AGE')
],
link=[
# Указываем связь, с помощью которой версии фичей будут добавлены в датасет
el.auto_link_CUSTOMER_x_CUSTOMER_AGREEMENT_1_M
]
)
Выполняем регистрацию датасета и запуск расчета:
Ручные связи сущностей
Помимо автоматических связей, которые образуются между сущностями с общими ключами, существуют ручные связи, которые представляют из себя таблицу с данными, в которой присутствуют оба набора ключей связываемых сущностей. Таким образом с помощью ручной связи можно соединить любые сущности.
Ручная связь зерен это источник данных о связи сущностей, поэтому для регистрации в приложении используем загрузчик.
Зарегистрируем связь M:N (многие ко многим) между сущностями CUSTOMER и CUSTOMER_AGREEMENT,
т.к. известно, что в таблице customer_x_customer_agreement_inhouse
содержатся договора между клиентами фирмы, что значит на один и тот же договор приходится
больше 1 клиента и на каждого клиента не меньше 1 договора.
new_entity_link = load.create(source='table', target='entity_link')
new_entity_link.config = {
'loader_name': 'CUSTOMER_X_CUSTOMER_AGREEMENT_M_N',
'description': 'Связи клиентов с договорами внутри фирмы',
'src_schema_name': 'stage',
'src_table_name': 'customer_x_customer_agreement_inhouse',
'kind': 'M:N',
'parent_entity': ent.CUSTOMER,
'child_entity': ent.CUSTOMER_AGREEMENT
}
new_entity_link.mapping = {
'from_dttm': 'from_dttm',
'parent': [ # <-- задаем маппинг для первой сущности CUSTOMER
{
'entity_key': ent.CUSTOMER.CUSTOMER_RK,
'stg_column_name': 'customer_rk'
}
],
'child': [ # <-- задаем маппинг для второй сущности CUSTOMER_AGREEMENT
{
'entity_key': ent.CUSTOMER_AGREEMENT.CUSTOMER_RK,
'stg_column_name': 'customer_rk_ca'
},
{
'entity_key': ent.CUSTOMER_AGREEMENT.AGREEMENT_RK,
'stg_column_name': 'agreement_rk_ca'
}
]
}
new_entity_link.save_x_execute()
Исходные данные
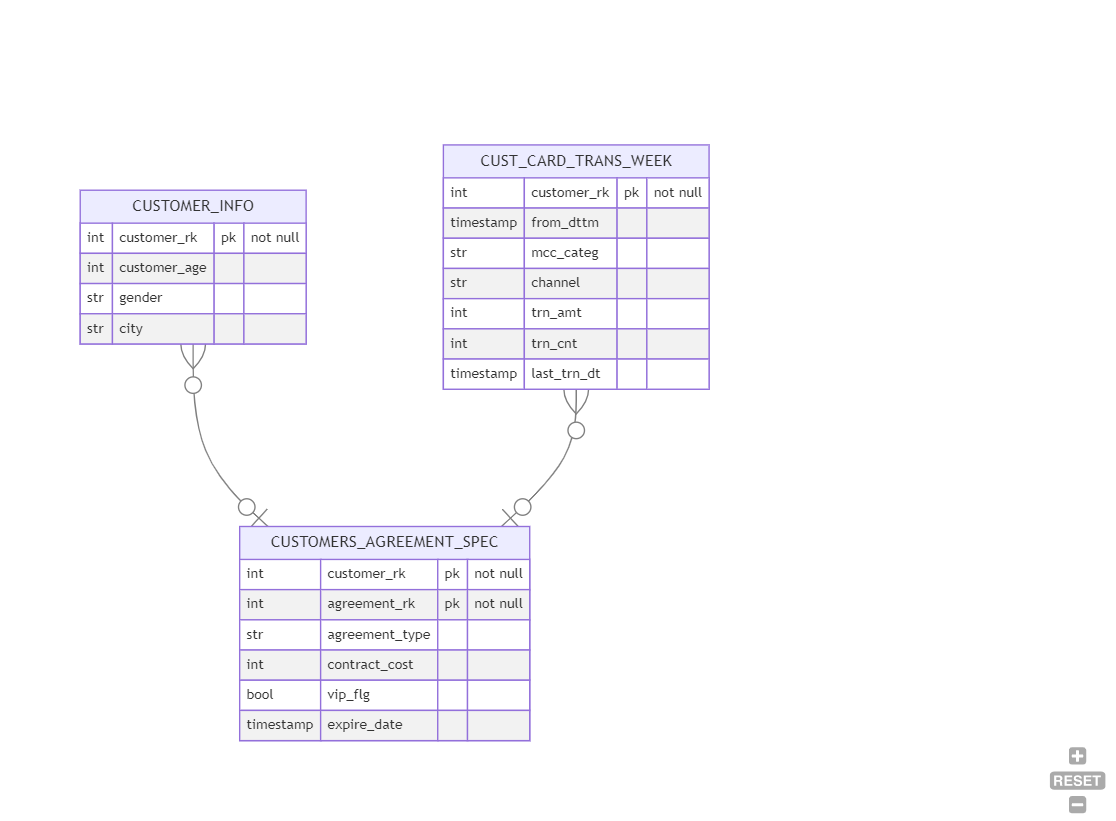
CUSTOMER_INFO- данные по конкретному клиенту - пол, возраст, город.CUST_CARD_TRANS_WEEK- данные о количестве и сумме транзакций клиента за неделю в разрезе товарных категорий и каналов распространения.CUSTOMERS_AGREEMENT_SPEC- данные о договорах между клиентом и фирмой: тип договора, стоимость, признак "Вип", дата окончания договора.