Создание датасета
Пример регистрации датасета с использованием разных видов трансформаций данных, после которого будет разобран каждый шаг подробнее.
new_dataset = ds.create(
# Сущность нового датасета
entity=ent.CUSTOMER,
# Название датасета в каталоге
name='PURCHASE_NORMAL',
# Пользовательское описание датасета
description='str'
)
# Готовые фичи
new_dataset.add_feature(
features=[
feat.CUSTOMER_NAME.ADM_V1.alias('NAME'),
feat.AGE.ADM_V1.alias('AGE')
]
)
# Агрегация с условием фичей предагрегатов
new_dataset.add_feature(
features=[
feat.PRICE.STORE_1.alias('PRICE')
],
agg=[ # список агрегирующих функций
func.sum(),
func.max(),
func.min()
],
domain=[
(feat.BONUS_PAYMENT.STORE_1 == True).set(alias='BP'),
(feat.CATEGORY.STORE_1 == 'FOOD').set(alias='FOOD'),
(feat.CATEGORY.STORE_1 == 'CLOTHES').set(alias='CLOTHES')
],
link=[
el.CUSTOMER_X_PURCHASE_STORE_1
]
)
# Составные фичи (фичи 2-го уровня)
ds_feat = new_dataset.get_features() # <-- каталог фичей датасета
new_dataset.add_feature(
(
(ds_feat.SUM_PRICE_BP_FOOD - ds_feat.MIN_PRICE_BP_FOOD) / (ds_feat.MAX_PRICE_BP_FOOD - ds_feat.MIN_PRICE_BP_FOOD)
).alias('PRICE_BP_FOOD_FOOD_NORMA')
)
# Фильтрация датасета
ds_feat = new_dataset.get_features()
new_dataset.filter = (ds_feat.AGE > 18) & (ds_feat.AGE <= 65)
# Регистрация
new_dataset.save_x_execute()
Готовые фичи
new_dataset.add_feature(
features=[
feat.CUSTOMER_NAME.ADM_V1.alias('NAME'),
feat.AGE.ADM_V1.alias('AGE')
]
)
Готовые фичи добавляются в датасет as-is с возможностью указать алиас для них в итоговом датасете, как указано в примере.
Если фичи зарегистрированы под другой сущностью, в аргумент link передается связь сущностей
или цепочка связей сущностей. Цепочка связей всегда должна приводить
от сущности датасета к сущности фичи или фичей, указанных в features.
Использование связи сущностей может потребовать агрегации готовой фичи в следующих случаях:
- Использована связь M:N
- Использована связь 1:M, где дочерняя сущность (M) - сущность фичи
В таких ситуациях работать с фичами как с предагрегатами (см. "Предагрегаты").
Альтернативный вариант добавления готовых фичей в датасет:
Предагрегаты
new_dataset.add_feature(
features=[
feat.PRICE.STORE_1.alias('PRICE')
],
agg=[ # список агрегирующих функций
func.sum(),
func.max(),
func.min()
],
domain=[
(feat.BONUS_PAYMENT.STORE_1 == True).set(alias='BP'),
(feat.CATEGORY.STORE_1 == 'FOOD').set(alias='FOOD'),
(feat.CATEGORY.STORE_1 == 'CLOTHES').set(alias='CLOTHES')
],
link=[
el.CUSTOMER_X_PURCHASE_STORE_1
]
)
Для добавления предагрегатов в датасет требуется указать функции агрегации в аргумент agg.
Набор доступных функций агрегации — см. глава "Функции агрегации".
Условия, передаваемые в аргумент domain, будут использованы в операторе CASE
внутри указанных функций агрегации.
Для составления условий могут быть использованы функции модуля
functions (см. глава "Функции трансформации").
В примере выше мы получим 6 фичей в датасете:
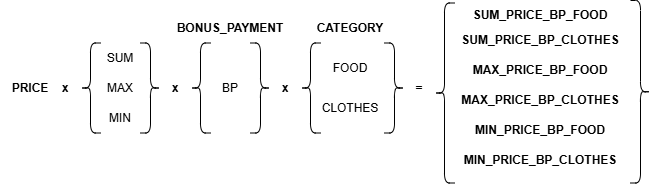
Фичи, которые могут быть использованы в условиях:
- Готовые фичи
- Любые фичи, которые загружены одним загрузчиком с фичами в списке
features
В аргументе link передается связь сущностей или цепочка связей сущностей если используемый
предагрегат зарегистрирован под другой сущностью. Цепочка связей всегда должна приводить
от сущности датасета к сущности фичи или фичей, указанных в features.
В аргумент features при агрегации можно передать несколько фич-предагрегатов. В таком случае
к ним будут применены одинаковые функции, условия и связи сущностей. При этом фичи должны быть
зарегистрированы под одинаковой сущностью.
Составные фичи (фичи 2 уровня)
ds_feat = new_dataset.get_features() # <-- каталог фичей датасета
new_dataset.add_feature(
(
(ds_feat.SUM_PRICE_BP_FOOD - ds_feat.MIN_PRICE_BP_FOOD) / (ds_feat.MAX_PRICE_BP_FOOD - ds_feat.MIN_PRICE_BP_FOOD)
).alias('PRICE_BP_FOOD_FOOD_NORMA')
)
Составные фичи получаются из фичей датасета. Для создания такой фичи требуется
получить каталог фичей датасета ds_feat. Доступный набор функций см. глава "Функции трансформаций".
Для составных фичей обязательно указания алиаса, как в примере.
Фильтрация датасета
Фильтрация датасета осуществляется фичами датасета. Возможности трансформаций полностью соответствуют функционалу получения составных фичей.
Переданное выражение попадает в условие WHERE при расчете датасета,
поэтому его результат должен быть булевым.
Функции агрегирования
Все функции представлены в модуле function, пример использования:
new_dataset.add_feature(
features=[
feat.PRICE.STORE_1.alias('PRICE')
],
agg=[
func.sum(),
func.max(),
func.min()
]
)
sum()avg()max()min()count()count_distinct()
Функции трансформаций
Все функции представлены в модуле function, пример использования функции between:
ds_feat = my_ds.get_features()
my_ds.add_feature(
(
func.between(ds_feat.AGE, 18, 35)
).alias('test_feature_between')
)
and_(<feature expression (bool) 1>, .., <feature expression (bool) N>)or_(<feature expression (bool) 1>, .., <feature expression (bool) N>)all(<feature 1>, .. <feature N>)between(<feature>, <left value>, <right value>)case((<WHEN feature expression 1>, <THEN value 1>), .. , else_=<ELSE value, default NULL>)ceil(<feature>)coalesce(<feature 1>, .. , <feature N>, _else=<ELSE value>)concat(<feature 1>, .., <feature N>)concat_ws(<feature 1>, .., <feature N>, sep=<separate value>)date_add( <feature>, year=<years count>, month=<months count>, week=<weeks count>, day=<days count>, hour=<hours count>, minute=<minutes count>, second=<seconds count> )date_sub( <feature>, year=<years count>, month=<months count>, week=<weeks count>, day=<days count>, hour=<hours count>, minute=<minutes count>, second=<seconds count> )date_part(<feature>, unit=<unit value ex. 'century', 'day', 'month'>)date_trunc(<feature>, field=<trunc value ex. 'minute', 'year'>)floor(<feature>)length(<feature>)like(<feature>, <like value>)like_any(<feature>, <like value>)like_not(<feature>, <like value>)ln(<feature>)log(<feature>)ltrim(<feature>)replace(<feature>, to_replace=<replace value>, replacement_string=<replase TO value>)reverse(<feature>)rtrim(<feature>)sqrt(<feature>)strpos(<feature>, substring=<sub string value>)substr(<feature>, start_pos=<START value, defatult=1>, length=<LENGTH value, default=None>)lower(<feature>)translate(<feature>, str_to_replace=<replace value>, replacement_str=<replace TO value>)trim(<feature>, trim_str=<trim value>, trim_type=<one of ['leading', 'trailing', 'both']>)trunc(<feature>, digit=<DIGIT value, default 0>)upper(<feature>)